TrueNAS Core
In part 1 I cover some basic ZFS theory and the layout of a high performance ZFS pool for ESXi VM block storage. I will be using TrueNAS Core, which in my opinion is hands down the best free storage platform on the market and it is open source. TrueNAS Core will give the big boys a run for their money.
TrueNAS Core runs on FreeBSD a very stable OS and uses the OpenZFS file system. It has an excellent web based user interface that is very intuitive. My only complaint is that iXsystems the maker of TureNAS Core does not allow the configuration of Fibre Channel from the GUI as this is restricted to TrueNAS Enterprise which is only available with the official TrueNAS hardware.
ZFS
ZFS is an advanced file system that offers many beneficial features such as pooled storage, data scrubbing and integrity checking, redundancy, scale and more. One of the most beneficial and miss understood features of ZFS is the way it caches reads and writes. ZFS allows for tiered caching of data through the use of system RAM, NVMe and SSDs. ZFS is a very powerful storage system and if you build the pool right ZFS can give you great performance, but with great power comes great responsibility, just because ZFS allows you to do something does not mean you should.
Special VDEVs & Caching
Pools can make use of special purpose VDEVs to improve the performance of the pool that they are attached to. We will be focusing on the L2ARC and SLOG in this blog. Newer versions of ZFS have added Metadata and dedup table VDEVs
Reads
System RAM is the top tier of caching in ZFS. Adaptive Replacement Cache (ARC) is held in RAM and is where ZFS places the most recently and frequently read data and being RAM, reads are lightning fast. When all of the space in the ARC is utilised, ZFS places the less frequently used data into the Level 2 Adaptive Replacement Cache (L2ARC) if used, which can be any GEOM provider but NVMe is best. The ARC and L2ARC are used to speed up reads so that the system doesn’t need to go searching through slow spinning disks every time it needs to find data.
Writes
For writes it’s a little more complicated and it depends on whether the writes are asynchronous or synchronous and we will explore these in more detail. First lets try an understand the ZIL, SLOG, TXGs and COW.
ZIL
ZFS maintains a ZFS Intent Log (ZIL) that is part of the pool. The purpose of the ZIL is to log synchronous writes to disk before they are written to permanent storage on your array. Essentially this is how you can be sure that an operation is completed and the write is safe on persistent storage instead of cached in volatile memory. The most important thing to emphasise from a performance perspective is that the ZIL is located on the main storage pool by default.
SLOG
The ZIL is a big drag on synchronous write performance and ZFS gives you the option to move the ZIL off the main pool to a VDEV called a SLOG (Separate Log) device. By adding a NVMe SLOG synchronous writes happen much faster and it also frees up the main storage pool to service other storage IO requests.
COW
On most file systems, data is irreversibly lost during the overwrite operation when updating a file. On ZFS, however, the data changes are performed on a copy of the data instead of the original data blocks. In other words, the changes are stored on a different location on a disk and then the metadata is updated to point to the new block. If snapshots are not used the old block is marked as free.
This mechanism guarantees that the old data is safely preserved in case of power loss or system crash that in other cases would result in loss of data. On other file systems, the data would be left in an inconsistent state and the Linux and Unix fsck command would have to be run to ensure that data is not corrupted. Could you imagine running fsck on a 500TB pool?
TXGs
ZFS groups write data into Transaction Groups (TXGs) before flushing them out to permanent storage in intervals of 5 seconds or when a predefined size limit is reached. The default time and the size can be changed to suit the workload.
By grouping smaller writes in to larger groups of sequential writes, ZFS increases performance with writes going to disk because they are better organised and therefore much easier for spinning disks to process.
Asynchronous vs Synchronous Writes
ZFS will have terrible performance for synchronous write workloads and protocols like NFS if not designed correctly. To understand the basics of how ZFS handles writes, you will need to understand the difference between synchronous and asynchronous writes.
Asynchronous Writes
When the client sends out a write request to the storage server, it is immediately stored in RAM. The server will then acknowledges to the client that the write has been committed to stable storage, in essence ZFS is lying to the client. ZFS will continue accepting write requests without writing anything to the disks until the transaction group time out or size is reached and only then is the data flushed to stable storage. Asynchronous writes appear very fast from the end users perspective because the data only needs to be stored in high speed RAM to be seen as completed.
Now if a power failure or kernel panic occurs then everything in the transaction group or in the process of being flushed to disk will be lost, because it only exists in volatile memory. Up to 5 seconds worth of data would be lost. Now because ZFS is a COW file system your data on disk will still be consistent because ZFS does not overwrite blocks it writes to free space and then updates the block pointers and marks the old blocks as free.
This is the fastest write performance available to ZFS but it will still be limited by the underlying disk because ZFS has to flush the data from RAM to disk and if the data hitting RAM can’t be flushed before the next transaction group is full, IO will be paused while the disks catch up. So pool disk technology and layout is very important and will dictate the level of performance you will get for a given workload.
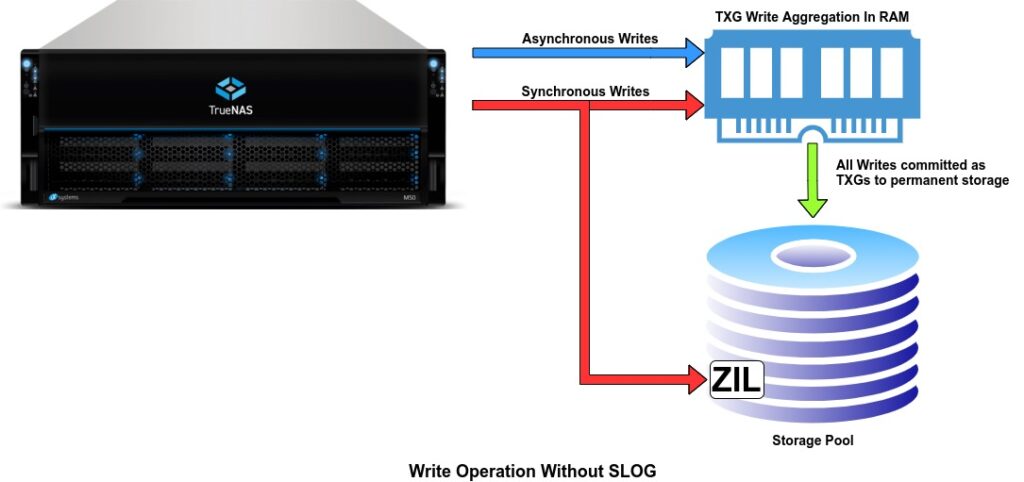
Synchronous Writes (without a separate log device)
When a client requests a synchronous write, it is still first sent to the RAM just like an asynchronous write, but the server will not acknowledge that the write has completed until it has been logged in the ZIL. Once the ZIL has been updated, then the write is acknowledged as committed to stable storage. Just as with asynchronous writes once the 5 second or size limit is reached the data has to be flushed from the ZIL to the final resting place on the pool.
The ZIL lives on your storage pool by default which means the drive heads needs to physically move location to both update the ZIL and actually store the data as part of the pool all while servicing read requests, further impacting performance. Waiting for slower storage media like spinning disks causes major performance issues, especially from small random reads & writes. If your client needs 1000 write IOPS you would need 2000 IOPS on the pool because the data is essentially being written twice. This behaviour will bring a ZFS pool to its knees when used for a random read/write workload or with protocols like NFS that default to sync writes. Even with an all flash pool this can become an issue under heavy load.
Synchronous Writes (with a separate log device)
ZFS’s solution to poor performance from synchronous writes is allowing the user to place the ZIL on a separate, faster, and persistent storage, known as Separate Log (SLOG) device and is typically a SSD or NVMe with PMEM the fastest option. Now the data is written to the SLOG and RAM, once the transaction group times out or its size limit is reached it will be flushed to permanent storage. This significantly speeds up the synchronous writes and depending on the device used for the SLOG you can get near asynchronous write speed with the safety of synchronous writes.
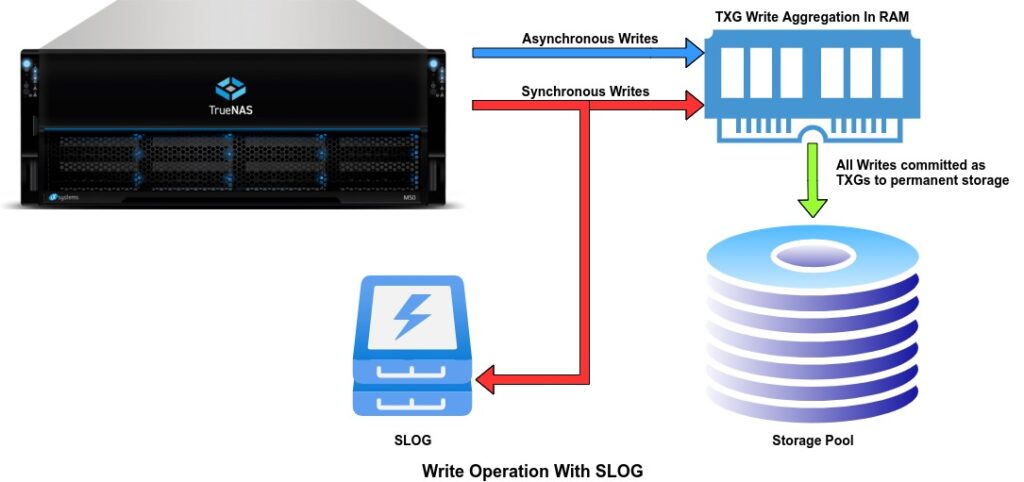
If you are going to use a SLOG then it is imperative to use a device that will maintain the data integrity that the ZIL is designed to. The device would need Power Loss Protection (PLP), high write endurance and a mirror vdev to protect against drive failure.
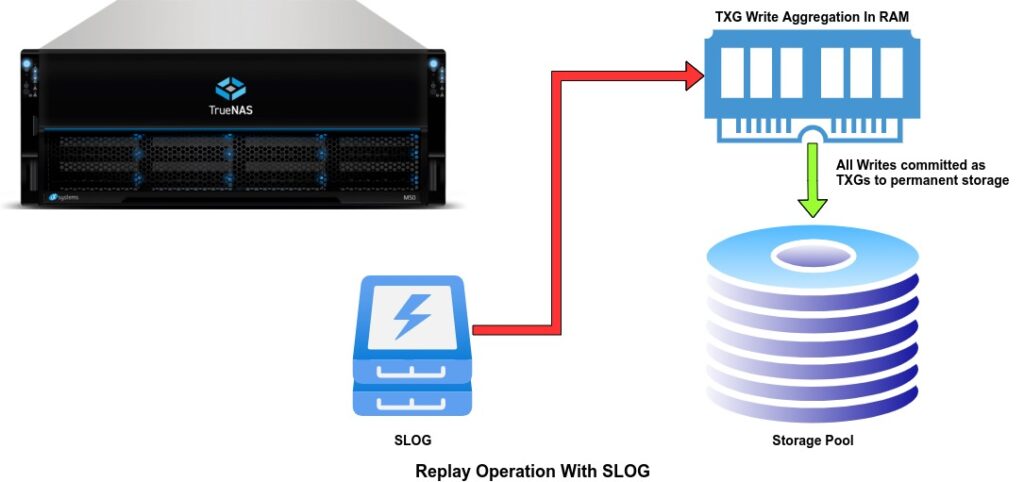
After a power failure or system crash when the server is rebooted ZFS will check the ZIL or SLOG to see if there is any dirty data present and if there is it will flush that to disk before importing the pool, this is the only time the ZIL/SLOG is read. Because there is only one process writing to the SLOG you will want a device with really good single q depth performance. NVMe and pMEM are best.
ZFS Pools & Fault Tolerance
ZFS has a number of advantages over traditional RAID systems with the biggest ones being that ZFS is both the volume manager, disk redundancy layer and file system. Traditionally the disks would be handled by a RAID controller which would group the physical disks into a virtual disk. They would then be presented to the OS which would handle the file system.
Pool Layout
The first order of business is to pick the best pool layout for your workload. The pool that I will create will be for ESXi VM storage so it will need good random read/write performance. For the best performance mirror VDEVs are best at the cost of usable space. I have determined that for my use case RAID Z the equivalent of RAID 5 will give me enough IOPS. I will have 4 RAID Z VDEVs of 5 SSDs with 2 hot spares. The SLOG will be high performance SSD and L2ARC will be a NVMe drive.
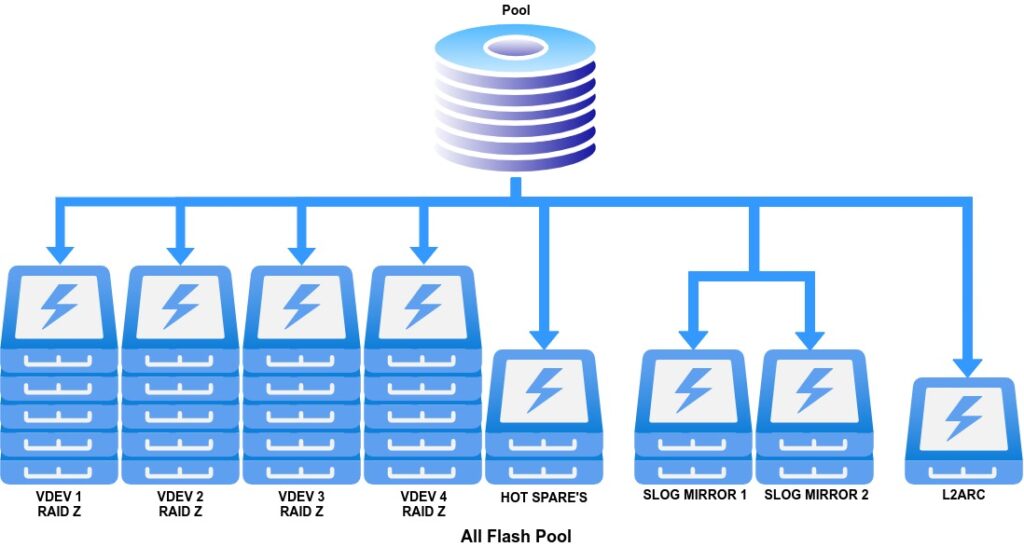
I will use the below devices to build out the pool.
The data VDEVs
HITACHI HGST 400GB 6Gb/s SAS SSD HUSML4040ASS600
Performance
- Read Throughput (max MB/s, sequential 64K) 495
- Write Throughput (max MB/s, sequential 64K) 385
- Read IOPS (max IOPS, random 4K) 56,000
- Write IOPS (max IOPS, random 4K) 24,000
The SLOG
Samsung SM1625 Series 200GB SSD SAS 6Gbps High Performance MZ-6ER200T/003
Performance
- Read Throughput (max MB/s, sequential 128K) 902
- Write Throughput (max MB/s, sequential 128K) 740
- Read IOPS (max IOPS, random 4K) 101,500
- Write IOPS (max IOPS, random 4K) 60,000
- Power loss protection Super Capacitor
L2ARC
Intel Optaine P900 280GB PCIe 3.0 x4 NVMe card
Performance
- Read Throughput (max MB/s, sequential) 2500
- Write Throughput (max MB/s, sequential) 2000
- Read IOPS (max IOPS, random 4K) 550,000
- Write IOPS (max IOPS, random 4K) 500,000
In part 2 we’ll be going through the process of setting up TrueNAS Core storage pool and setting up fibre channel target.
Links & Sources
A great write up by a TrueNAS forum member that should be read here and here.
Also read a blog post by iXsystems the makers of TureNAS here and the resource section here.
Great article by Serve The Home here.
The following three books are highly recommended if you want to get a better understanding of FreeBSD and ZFS. They should be read in the order listed.